In my previous post on sentiment I discussed the process of building data frames of chapter metrics and word lists. I will use the word data frame to monitor sentiment across the book. I am working with non-unique, non-stop, greater than 3 character words (red line from the previous post). Looking at the word list and comparing to text, I can see that the words are in the order that they appear in the novel. I will use the Bing sentiment determinations from the tidytext package to annotate each word as being either of positive or negative sentiment. I will then group by 15 words and calculate the average sentiment.
1 | ##make a dataframe of all chapters |
Plot as a line graph, with odd chapters colored black and even chapters colored grey. I also annotate a few moments of trauma within the narrative.
1 | library(ggplot2) |
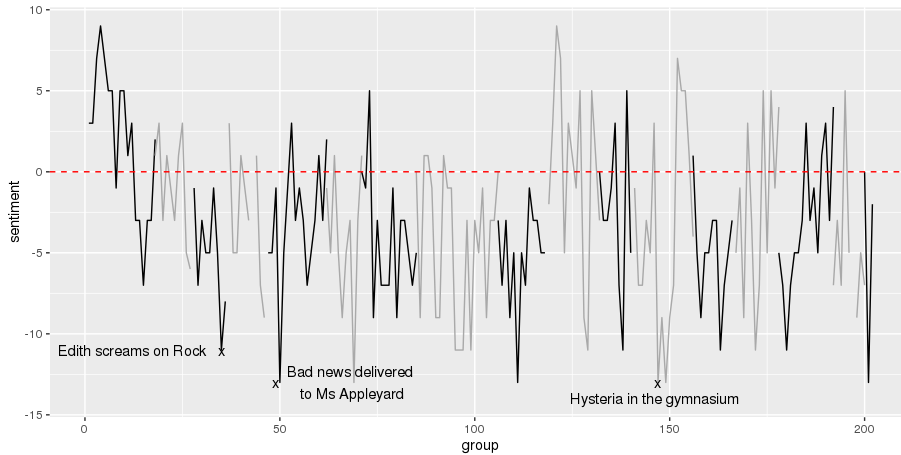
We can see that the novel starts with a positive sentiment - “Beautiful day for a picnic…” - which gradually moves into negative territory and remains there for the majority of the book.
Does sentiment analysis really work? Depends on how accurately word sentiment is characterized. Consider the word “drag”:
1 | > d2[d2$word=="drag",] |
There are many instances of the word drag annotated as negative. Consider the sentence “It’s a drag that sentiment analysis isn’t reliable.” That would be drag in a negative context. In Picnic, a drag is a buggy pulled by horses, mentioned many times, imparting lots of undeserved negative sentiment to the novel. Drag in Picnic is neutral and should have been discarded. Inspecting the sentiment annotated word list, many other examples similar to drag could be found, some providing negative, some positive sentiment, on average probably cancelling each other out. Even more abundant are words properly annotated, which, on balance may convey the proper sentiment. I would be skeptical, though, of any sentiment analysis without a properly curated word list.
In the next post I will look at what can be done with a corpus.